Publications
Here are my publications (including preprints).
2025
-
 Hayeon Kim*, Ji Ha Jang*, and Se Young ChunIn International Conference on Computer Vision (ICCV), 2025ICCV
Hayeon Kim*, Ji Ha Jang*, and Se Young ChunIn International Conference on Computer Vision (ICCV), 2025ICCVDue to limited 3D data, recent prior arts in Recent advances in 3D neural representations and instance-level editing models have enabled the efficient creation of high-quality 3D content. However, achieving precise local 3D edits remains challenging, especially for Gaussian Splatting, due to inconsistent multi-view 2D part segmentations and inherently ambiguous nature of Score Distillation Sampling (SDS) loss. To address these limitations, we propose RoMaP, a novel local 3D Gaussian editing framework that enables precise and drastic part-level modifications. First, we introduce a robust 3D mask generation module with our 3D-Geometry Aware Label Prediction (3D-GALP), which uses spherical harmonics (SH) coefficients to model view-dependent label variations and soft-label property, yielding accurate and consistent part segmentations across viewpoints. Second, we propose a regularized SDS loss that combines the standard SDS loss with additional regularizers. In particular, an L1 anchor loss is introduced via our Scheduled Latent Mixing and Part (SLaMP) editing method, which generates high-quality part-edited 2D images and confines modifications only to the target region while preserving contextual coherence. Additional regularizers, such as Gaussian prior removal, further improve flexibility by allowing changes beyond the existing context, and robust 3D masking prevents unintended edits Experimental results demonstrate that our RoMaP achieves state-of-the-art local 3D editing on both reconstructed and generated Gaussian scenes and objects qualitatively and quantitatively, making it possible for more robust and flexible part-level 3D Gaussian editing.
@inproceedings{hayeon-2024-romap, author = {Kim*, Hayeon and Jang*, Ji Ha and Chun, Se Young}, note = {ICCV}, booktitle = {International Conference on Computer Vision (ICCV)}, howpublished = {ICCV}, title = {RoMaP: Robust 3D-Masked Part-level Editing in 3D Gaussian Splatting with Regularized Score Distillation Sampling}, year = {2025}, eprint = {2507.11061}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, } -
 Dong Un Kang, Hayeon Kim, and Se Young ChunIn The Thirteenth International Conference on Learning Representations (ICLR), 2025ICLR
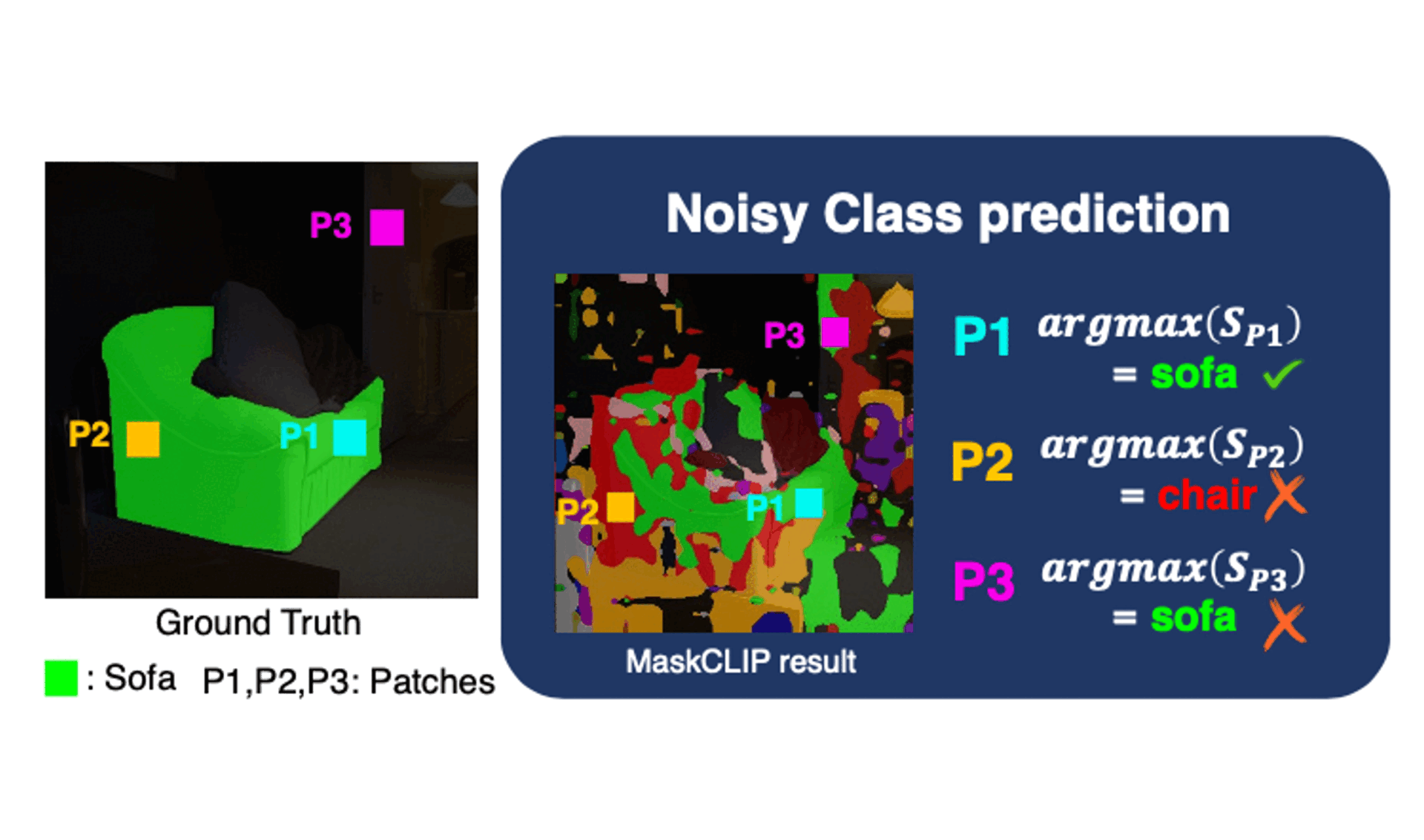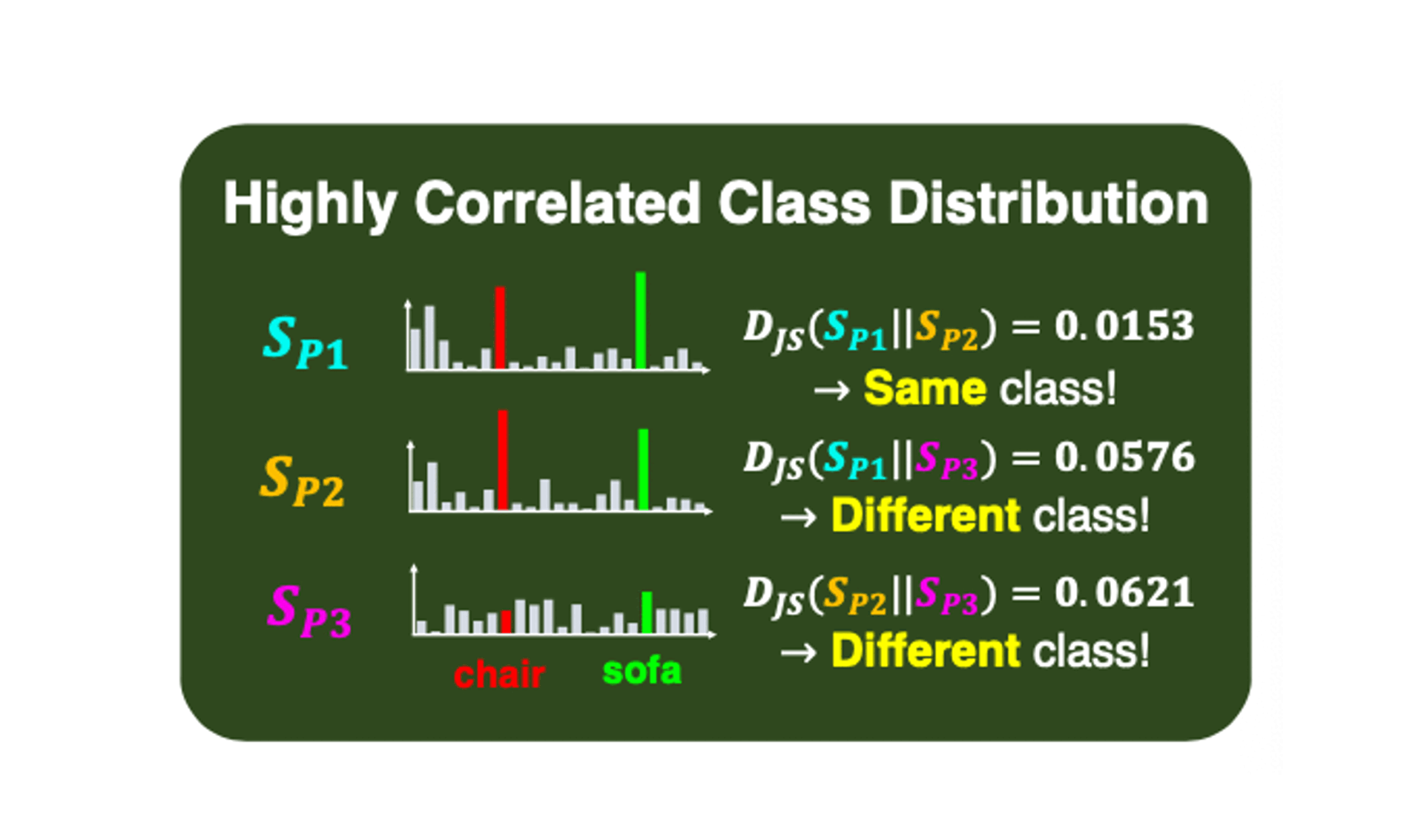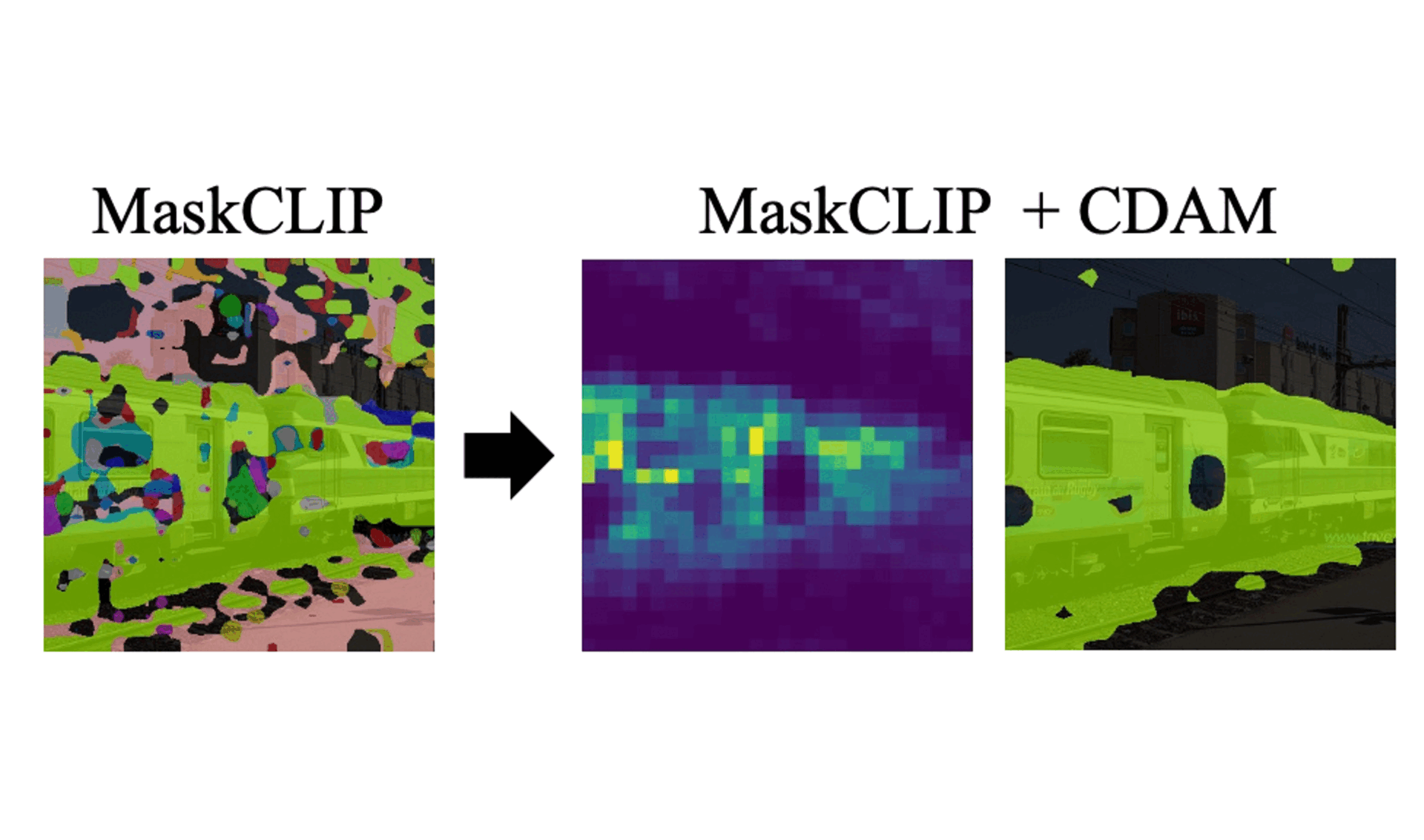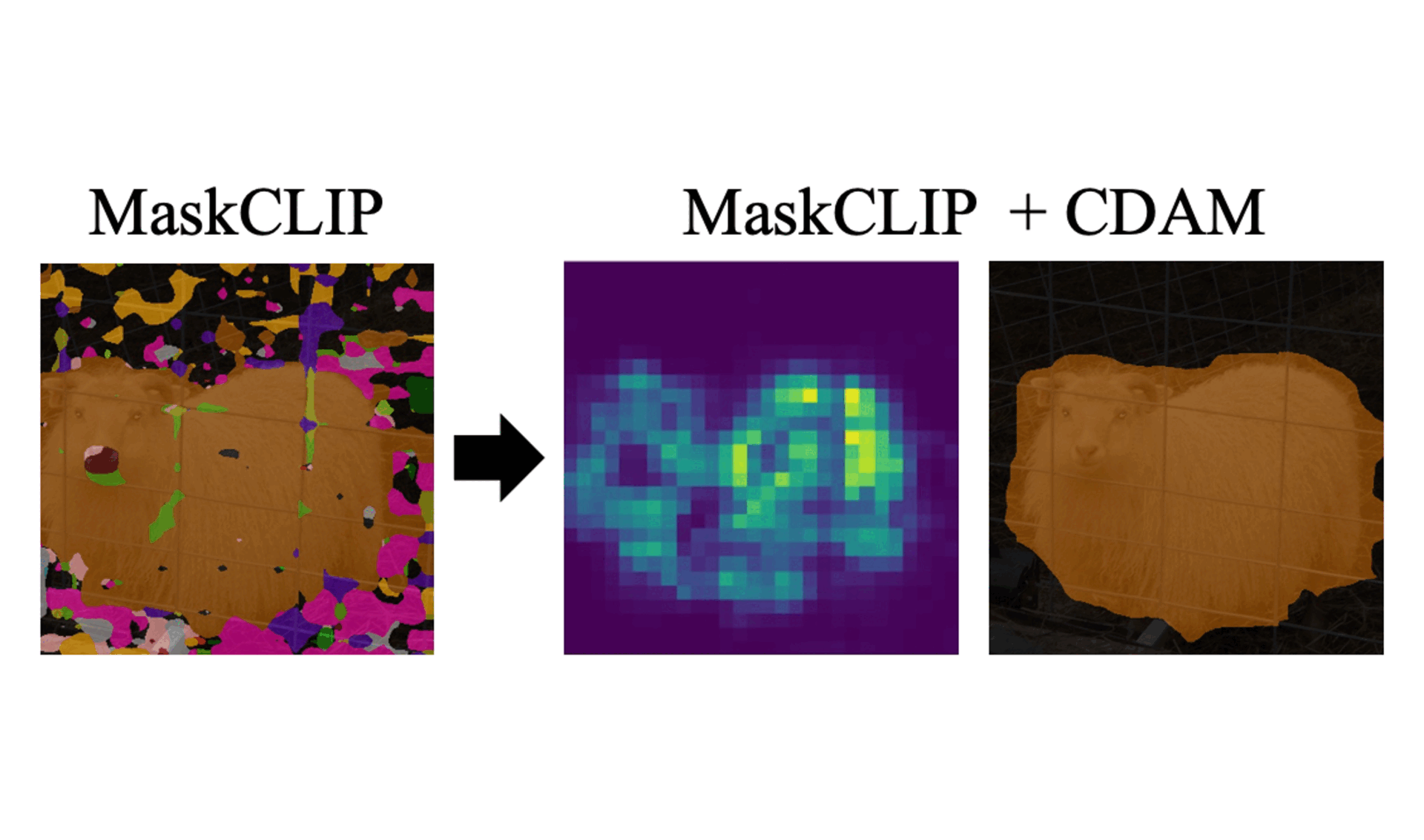
Dong Un Kang, Hayeon Kim, and Se Young ChunIn The Thirteenth International Conference on Learning Representations (ICLR), 2025ICLROpen-vocabulary semantic segmentation is a challenging task that assigns seen or unseen class labels to individual pixels. While recent works with vision-language models (VLMs) have shown promising results in zero-shot semantic segmentation, they still struggle to accurately localize class-related objects. In this work, we argue that CLIP-based prior works yield patch-wise noisy class predictions while having highly correlated class distributions for each object. Then, we propose Class Distribution-induced Attention Map, dubbed CDAM, that is generated by the Jensen-Shannon divergence between class distributions of two patches that belong to the same (class) object. This CDAM can be used for open-vocabulary semantic segmentation by integrating it into the final layer of CLIP to enhance the capability to accurately localize desired classes. Our class distribution-induced attention scheme can easily work with multi-scale image patches as well as augmented text prompts for further enhancing attention maps. By exploiting class distribution, we also propose robust entropy-based background thresholding for the inference of semantic segmentation. Interestingly, the core idea of our proposed method does not conflict with other prior arts in zero-shot semantic segmentation, thus can be synergetically used together, yielding substantial improvements in performance across popular semantic segmentation benchmarks.
@inproceedings{hayeon-2024-iclr, author = {Kang, Dong Un and Kim, Hayeon and Chun, Se Young}, note = {ICLR}, booktitle = {The Thirteenth International Conference on Learning Representations (ICLR)}, howpublished = {ICLR}, title = {CDAM: Class Distribution-induced Attention Map for Open-vocabulary Semantic Segmentations}, year = {2025}, primaryclass = {cs.LG}, }


2024
-
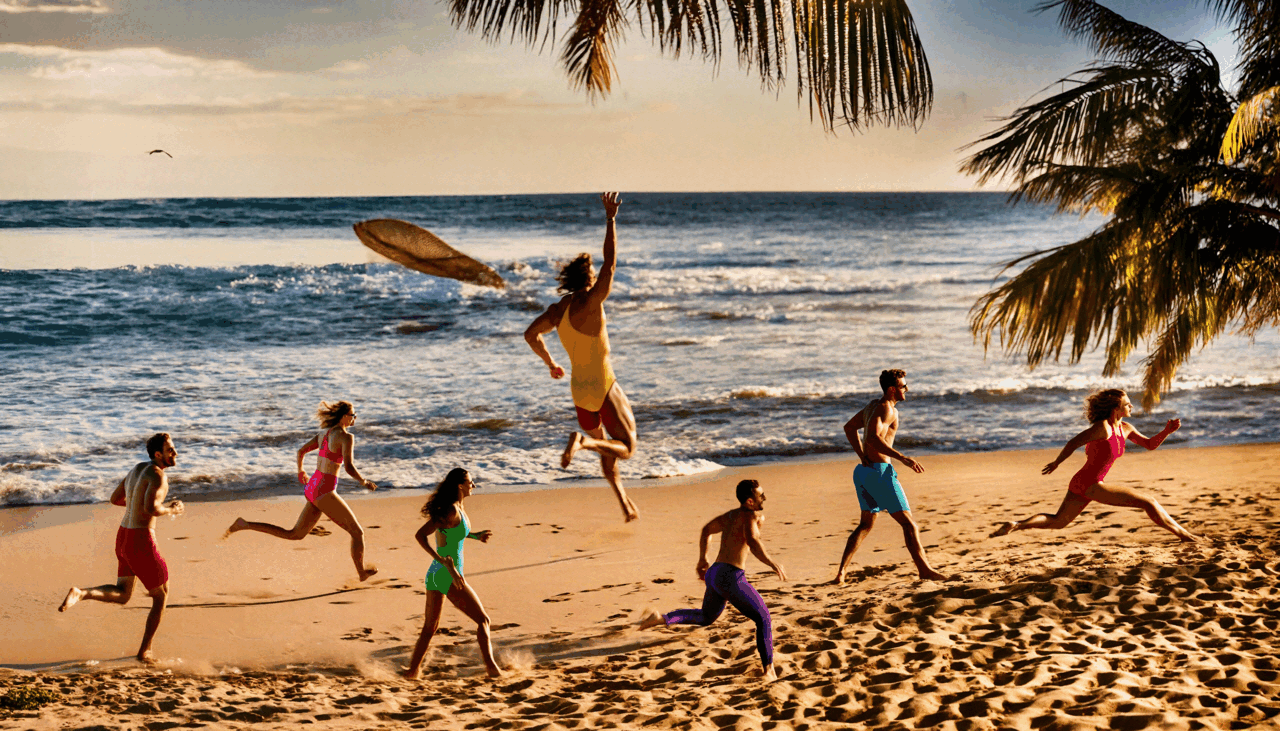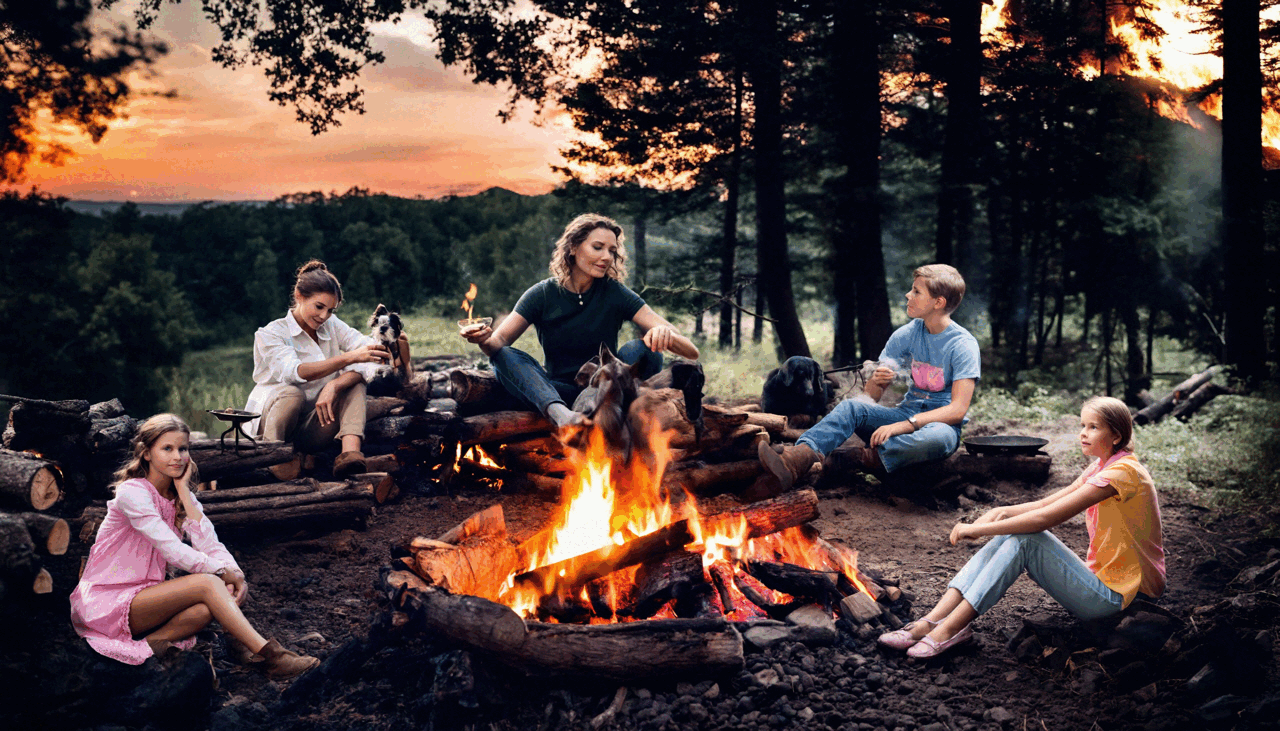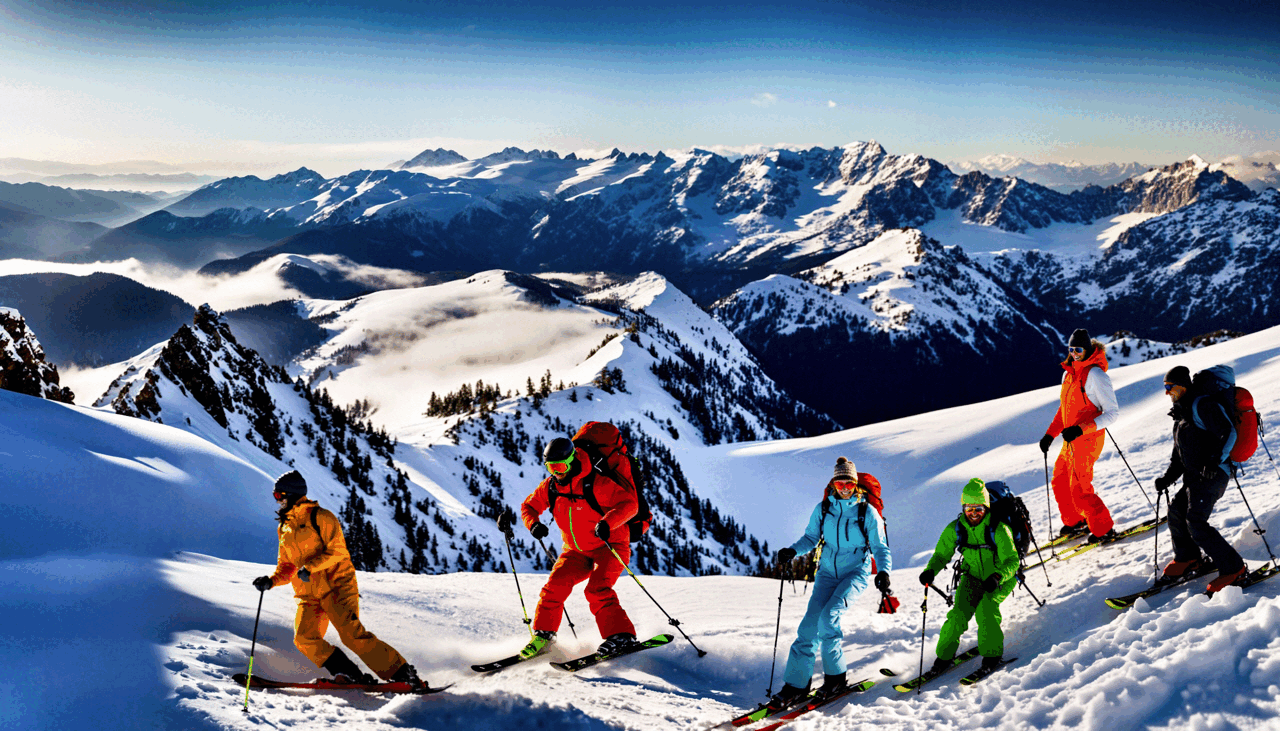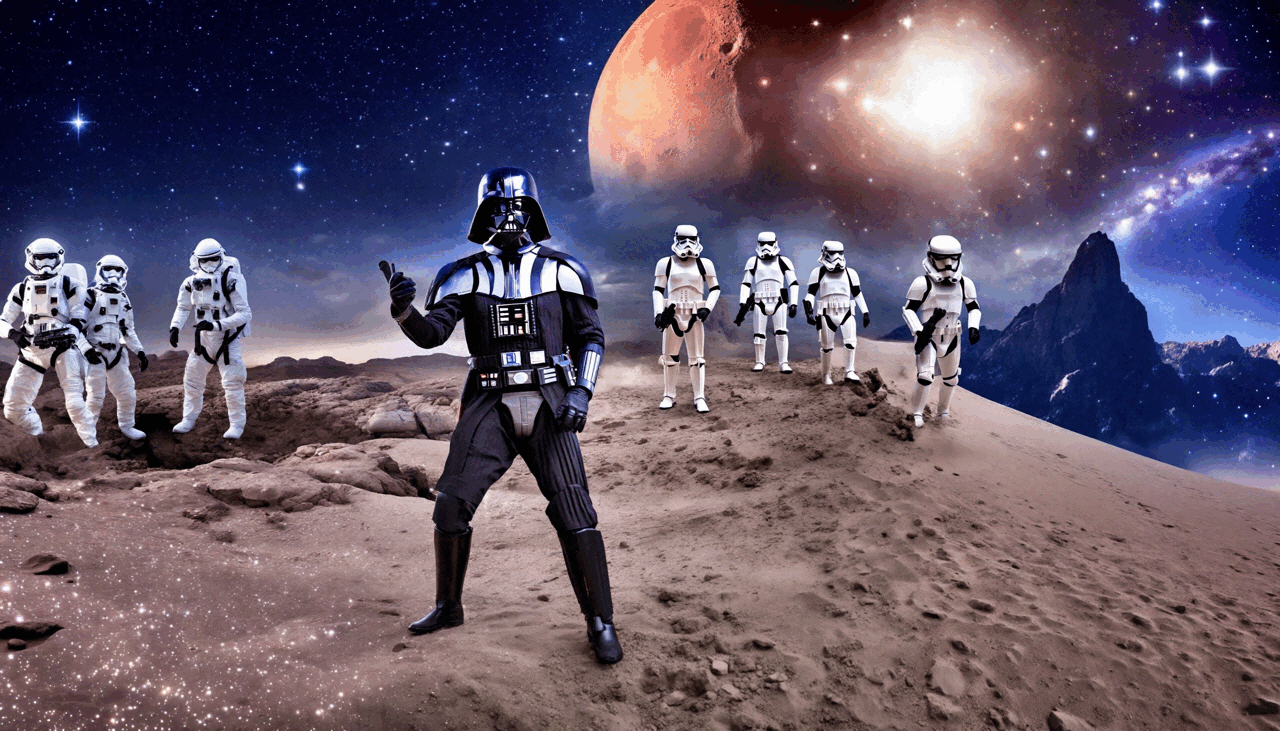 Hayeon Kim*, Gwanghyun Kim*, Hoigi Seo*, Dong Un Kang*, and 1 more authorIn European Conference on Computer Vision (ECCV), 2024ECCV
Hayeon Kim*, Gwanghyun Kim*, Hoigi Seo*, Dong Un Kang*, and 1 more authorIn European Conference on Computer Vision (ECCV), 2024ECCVGenerating higher-resolution human-centric scenes with de- tails and controls remains a challenge for existing text-to-image diffusion models. This challenge stems from limited training image size, text en- coder capacity (limited tokens), and the inherent difficulty of generat- ing complex scenes involving multiple humans. While current methods attempted to address training size limit only, they often yielded human- centric scenes with severe artifacts. We propose BeyondScene, a novel framework that overcomes prior limitations, generating exquisite higher- resolution (over 8K) human-centric scenes with exceptional text-image correspondence and naturalness using existing pretrained diffusion mod- els. BeyondScene employs a staged and hierarchical approach to initially generate a detailed base image focusing on crucial elements in instance creation for multiple humans and detailed descriptions beyond token limit of diffusion model, and then to seamlessly convert the base image to a higher-resolution output, exceeding training image size and incorporating details aware of text and instances via our novel instance-aware hierar- chical enlargement process that consists of our proposed high-frequency injected forward diffusion and adaptive joint diffusion. BeyondScene sur- passes existing methods in terms of correspondence with detailed text descriptions and naturalness, paving the way for advanced applications in higher-resolution human-centric scene creation beyond the capacity of pretrained diffusion models without costly retraining.
@inproceedings{hayeon-2024-beyondscene, author = {Kim*, Hayeon and Kim*, Gwanghyun and Seo*, Hoigi and Kang*, Dong Un and Chun, Se Young}, note = {ECCV}, booktitle = {European Conference on Computer Vision (ECCV)}, howpublished = {ECCV}, title = {BeyondScene: Higher-Resolution Human-Centric Scene Generation With Pretrained Diffusion}, year = {2024}, eprint = {2404.04544}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, } -
 Hayeon Kim Dongwon Park, and Se Young ChunIn European Conference on Computer Vision (ECCV), 2024ECCV
Hayeon Kim Dongwon Park, and Se Young ChunIn European Conference on Computer Vision (ECCV), 2024ECCVRecently, pre-trained model and efficient parameter tuning have achieved remarkable success in natural language processing and high-level computer vision with the aid of masked modeling and prompt tuning. In low-level computer vision, however, there have been limited in- vestigations on pre-trained models and even efficient fine-tuning strategy has not yet been explored despite its importance and benefit in various real-world tasks such as alleviating memory inflation issue when inte- grating new tasks on AI edge devices. Here, we propose a novel efficient parameter tuning approach dubbed contribution-based low-rank adap- tation (CoLoRA) for multiple image restorations along with effective pre-training method with random order degradations (PROD). Unlike prior arts that tune all network parameters, our CoLoRA effectively fine- tunes small amount of parameters by leveraging LoRA (low-rank adap- tation) for each new vision task with our contribution-based method to adaptively determine layer by layer capacity for that task to yield comparable performance to full tuning. Furthermore, our PROD strat- egy allows to extend the capability of pre-trained models with improved performance as well as robustness to bridge synthetic pre-training and real-world fine-tuning. Our CoLoRA with PROD has demonstrated its superior performance in various image restoration tasks across diverse degradation types on both synthetic and real-world datasets for known and novel tasks.
@inproceedings{hayeon-2024-colora, author = {Dongwon Park, Hayeon Kim and Chun, Se Young}, note = {ECCV}, howpublished = {ECCV}, booktitle = {European Conference on Computer Vision (ECCV)}, title = {Contribution-based Low-Rank Adaptation with Pre-training Model for Real Image Restoration}, year = {2024}, eprint = {2408.01099}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, }


2023
-
 Hayeon Kim*, Hoigi Seo*, Gwanghyun Kim*, and Se Young ChunIn , 2023arXiv
Hayeon Kim*, Hoigi Seo*, Gwanghyun Kim*, and Se Young ChunIn , 2023arXivThe increasing demand for high-quality 3D content creation has motivated the development of automated methods for creating 3D object models from a single image and/or from a text prompt. However, the reconstructed 3D objects using state-of-the-art image-to-3D methods still exhibit low correspondence to the given image and low multi-view consistency. Recent state-of-the-art text-to-3D methods are also limited, yielding 3D samples with low diversity per prompt with long synthesis time. To address these challenges, we propose DITTO-NERF, a novel pipeline to generate high-quality 3D NeRF model from a text prompt or a single image. Our DITTO-NERF consists of constructing high-quality partial 3D object for limited in-boundary (IB) angles using the given or text-generated 2D image from the frontal view and then iteratively reconstructing the remaining 3D NeRF using inpainting latent diffusion model. We propose progressive 3D object reconstruction schemes in terms of scales (low to high resolution), angles (IB angles initially to outer-boundary (OB) later) and masks (object to background boundary) in our DITTO-NERF so that high-quality information on IB can be propagated into OB. Our DITTO-NERF outperforms state-of-the-art methods in terms of fidelity and diversity qualitatively and quantitatively with much faster training times than prior arts on image / text-to-3D such as Dreamfusion, NeuralLift-360.
@inproceedings{hayeon-2023-ditto, author = {Kim*, Hayeon and Seo*, Hoigi and Kim*, Gwanghyun and Chun, Se Young}, note = {arXiv}, howpublished = {arXiv}, title = {DITTO-NeRF: Diffusion-based Iterative Text To Omni-directional 3D Model}, year = {2023}, eprint = {2304.02827}, archiveprefix = {arXiv}, primaryclass = {cs.LG}, }
